
Regex (정규표현식)
정규식이란
Regex (regular expression, regex, regexp, or rational expression, 정규표현식)은 특정한 텍스트 패턴을 표현하는 문자열입니다. 텍스트에서 특정한 패턴을 찾을 때 널리 쓰입니다.
배경
1950년대에 미국 수학자 Stephen Cole Kleene이라는 분이 ‘regular language(regex로 표현될 수 있는 형식언어)’라는 개념을 공식화 하셨습니다. 이후 1980년대부터 정규식을 표현하는 여러 문법이 만들어 졌습니다.
정규식은 여러 곳에서 쓰입니다.
먼저, Unix 시스템에서 텍스트 처리하는 곳(grep, sed)에서 쓰입니다.
Java, Python, JavaScript 등 다양한 프로그래밍 언어에서도 지원합니다.
비쥬 코드 같은 텍스트, 코드 에디터에서 어떤 특정 패턴의 단어를 찾을 때 사용 가능합니다.
이메일, 패스워드가 문자, 숫자, 특수문자 등을 가져야 하는 패턴을 가지는지 체크할 때도 정규식이 쓰입니다.
이 페이지는 많이 쓰이는 정규식 표현 몇 개를 소개합니다.
여러 사이트에서 가져온 정보를 포함합니다. 출처는 Reference 섹션에 표기했습니다.
Form
/regex?/i
/regex?/i: slash(/)로 ‘나는 정규식이야’라고 나타내 줍니다.- /패턴/: 2개의 slash 사이에 패턴을 작성합니다.
- /flag: 마지막 slash 옆에는 flag(i)를 작성해줍니다. flag는 어떤 옵션을 이용해서 검색할 것인지 넣을 수 있습니다.
Flags
- i
- case insensitive
- 영문 대소문자 구분 없이 검색합니다. (B와 b를 같은 취급 합니다)
- g
- global
- 패턴과 일치하는 모든 것들을 찾습니다.
- g 플래그가 없으면 패턴과 일치하는 첫 번째 결과만 찾습니다.
- m
- multiline (다중 행 모드)
- 문장의 첫 번째와 끝에 있는 패턴 검색할 때 문장이 어디서부터 시작하고 끝나는지 결정합니다.
- m 플래그가 없으면 주어진 텍스트 한 덩어리의 앞과 끝에 달린 패턴을 찾습니다. m 플래그가 있으면 각 문장의 앞과 끝의 패턴을 찾습니다.
- ^와 $를 사용할 때 작동 방식에 영향을 줍니다.
- s
- single line (dotall)
.이 개행 문자\n도 포함하도록 합니다.
- u
- unicode
- 유니코드 전체를 지원합니다.
- y
- sticky
- 문장 내 특정 위치에서 검색을 진행합니다.
보통 gm을 많이 쓴다고 합니다
Patterns
Groups and Ranges
| 또는
() 그룹
[] 문자셋, 괄호 안의 어떤 문자든
[^] 부정 문자셋, 괄호 안의 어떤 문자가 아닐 때
(?:) 찾지만 기억하지는 않음 (Non-capturing group)
Quantifiers
? 없거나 있거나 (zero or one) , 0/1
* 없거나 있거나 많거나 (zero or more) 0+
+ 하나 또는 많이 (one or more) 1+
{n} n번 반복
{min,} 최소
{min,max} 최소, 그리고 최대 [min, max]
Boundary-type
\b 단어 경계
\B 단어 경계가 아님
^ 문장의 시작
$ 문장의 끝
Character classes
\ 특수 문자가 아닌 문자
. 어떤 글자 (줄 바꿈 문자 제외)
\d digit 숫자
\D digit 숫자 아님
\w word 문자
\W word 문자 아님
\s space 공백
\S space 공백 아님
Examples
패턴에 대한 예제는 계속 업데이트 할 예정입니다.
Groups and Ranges
-
/Hi|Hello/gmHi there, Nice to meet you. And Hello there and hi my mine -
/(Hi|Hello)/gmHi there, Nice to meet you. And Hello there and hi. Hello모든 Hi, Hello 들은 group1으로 지정됩니다.
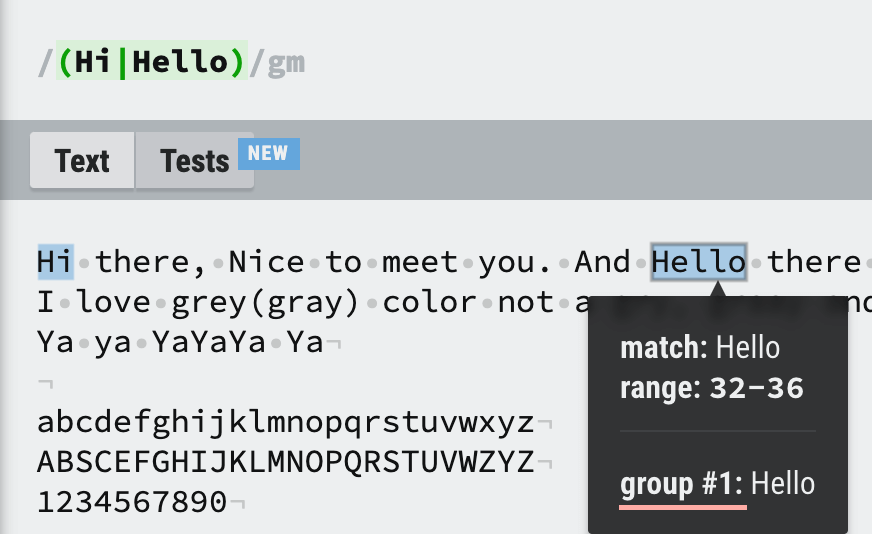
-
/(Hi|Hello)|(And)/gmHi there, Nice to meet you. And Hello there and hi. Hello모든 Hi, Hello 들은 group1으로, And는 group2로 지정됩니다.
-
/gr(e|a)y/gmI love grey(gray) color not a grdy, graay and graaay.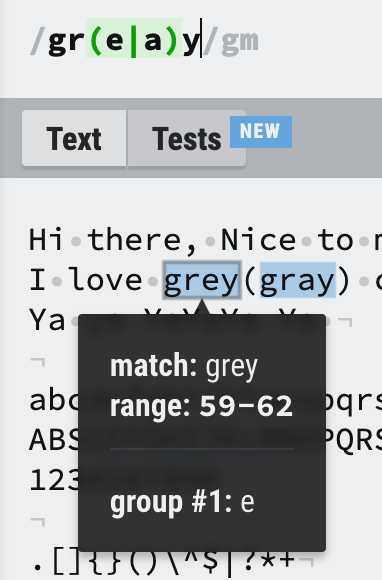
-
/gr[ead]y/gmI love grey(gray) color not a grdy, graay and graaay.대괄호에 있는 모든 문자열 집합체를 지정합니다.
-
/[a-f]/gmHi there, Nice to meet you. And Hello there and hi. -
/[a-zA-Z0-9]/gmHi there, Nice to meet you. 1234 -
/[^a-zA-Z0-9]/gmHi there, Nice to meet you. And Hello there and hi.not(부정하는) 부분을 의미합니다.
-
/gr(?:e|a)y/gmI love grey(gray) color not a grdy, graay and graaay.여러 토큰을 캡쳐 그룹을 생성하지 않고, group 지정 없이 찾습니다.
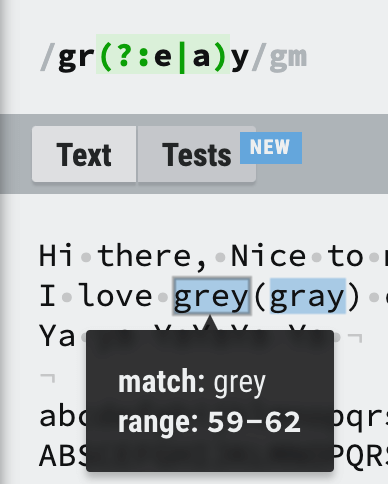
Quantifiers
-
/gra?y/gmI love grey(gray) color not a gry, graay and graaay.a가 있거나 없는 경우를(
a?) 찾습니다. -
/gra*y/gmI love grey(gray) color not a gry, graay and graaay.a*는 a가 없거나, 있거나, 많거나! -
/gra+y/gmI love grey(gray) color not a gry, graay and graaay.a+는 a가 있거나, 많거나! -
/gra{2}y/gmI love grey(gray) color not a gry, graay and graaay. -
/gra{2,3}y/gmI love grey(gray) color not a gry, graay and graaay. -
/gra{2,}y/gmI love grey(gray) color not a gry, graay and graaay. graaaaaaaaay
Boundary-type
-
/\bYa/gmYa ya YaYaYa Ya\b단어는 단어 앞에서만 선택됩니다. -
/Ya\b/gmYa ya YaYaYa Ya단어\b는 단어 뒤에서만 선택됩니다. -
/Ya\B/gmYa ya YaYaYa Ya단어\B는단어\b의 반대입니다. 단어 뒤에만 빼고! 뒤에서 쓰이지 않는 아이들만 선택됩니다. -
/^Ya/gmYa ya YaYaYa Ya
Yahello^Ya문장에서 시작하는Ya를 찾습니다. -
/Ya$/gmYa ya YaYaYa Ya
helloYaYa$문장 끝의Ya를 찾습니다. -
/Ya$/gYa ya YaYaYa Ya
helloYa
hellohelloYaflag
m을 뺀Ya$/g은 문장 전체에서 끝Ya를 찾습니다.
Leave a comment