
데이터베이스 DB 파티셔닝과 클러스터링
파티셔닝 (Partitioning)
- 용량이 큰 Table 이나 인덱스를 관리하기 쉬운 단위(partition)로 분리하는 방법
- 하나의 테이블에 많은 양의 데이터가 저장되면, 인덱스를 추가하고 테이블을 몇 개로 쪼개도 성능이 저하되는 경우일 때.
- 논리적으로는 하나의 테이블이지만, 물리적으로는 여러 개의 테이블로 분리
장점
- 가용성 (availability): 물리적 파티셔닝으로 전체 데이터 훼손 가능성이 줄어듬
- 관리용이성(manageability): 큰 테이블들 제거
- 성능(performance):
- 특정 DML과 Query 성능 향상: 데이터 액세스 성능 향상
- 주로 대용량 Data write 할 때 효율적. (많은 insert 작업들을 분리된 파티션으로 분산시켜 경합을 줄임)
단점
- Table 간의 Join 비용이 증가한다.
- 테이블과 인덱스를 별도로 파티션 불가. 테이블+인덱스를 같이 파티셔닝 해야함.
파티셔닝의 범위
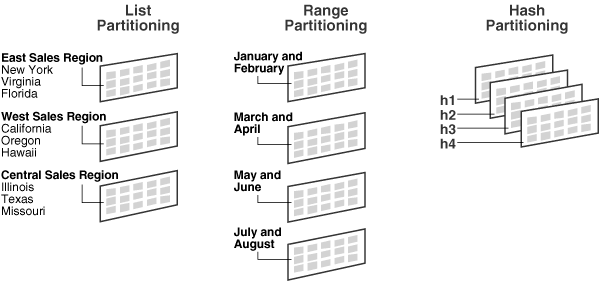
List partitioning (리스트 분할)
- 특정 partition에 저장될 Data에 대한 명시적 제어
- 특정 column의 특정 값으로 파티셔닝
- 유용 case: 비슷한 분포도 + 많은 SQL에서 해당 column 의 조건이 많이 들어오는 경우
- 예) 아시아- [한국, 중국, 일본]
- 여러 column(multi-column partition key)으로 partition key 생성하기 어려움. 오직 하나의 column으로 구성
Range partitioning (범위분할)
- 연속적인 숫자/날짜 기준
- 예) 일별, 월별, 분기별, 우편번호 등
- 손쉬운 관리 기법, 관리 시간 단축
- 특정 파티션에 데이터가 집중 될 수 있음
Hash partitioning
- partition key의 hash 값으로 partitioning
- 균등한 데이터 분할 가능 (범위분할 단점 보완)
- 질의 성능 향상: select 시 조건과 무관하게 병렬 처리
- 특정 Data 가 어느 hash partition에 있는지 판단 불가
- 유용 case: 파티션을 위한 범위가 없는 데이터 (기준, 조건 주기 힘들 때)
Composite partitioning
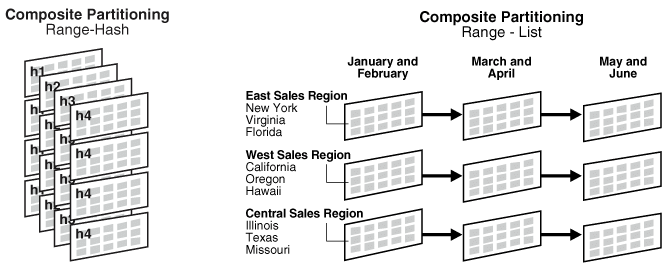
- partition의 sub-partitioning
- 큰 파티션에 대한 I/O요청을 여러 partition으로 분산
- 유용 case: 파티셔닝 결과 생성된 파티션이 너무 커서 효과적으로 관리 불가할 때
- 예) 범위분할 후 list(Range-list), 범위분할 후 hash (Range-Hash)
파티셔닝 방법
Horizontal Partitioning (수평분할)
테이블 행을 수평으로 쪼갠다.
데이터 개수를 기준으로 나누어 파티셔닝.
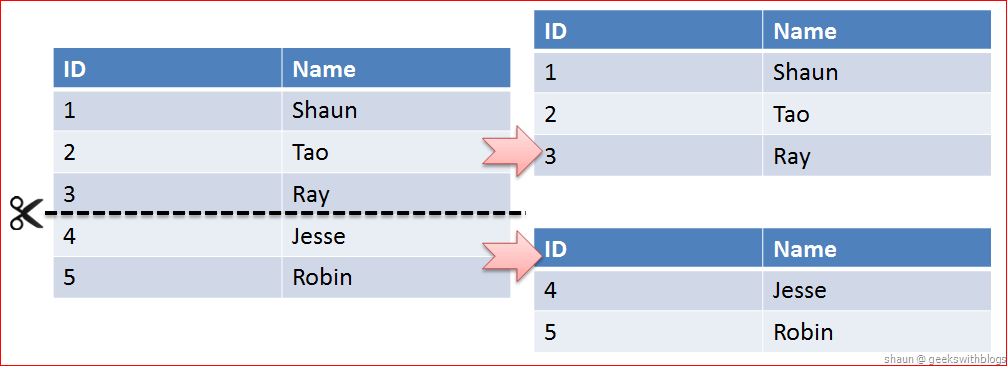
- 장점
- 데이터 개수가 작아지고 따라서 index의 개수도 작아지게 된다. 성능 향상.
- 단점
- 서버간의 연결과정이 많아진다.
- 데이터를 찾는 과정이 기존보다 복잡. latency(지연) 증가
Vertical Partitioning
테이블을 컬럼을 기준으로 나누어 쪼갠다.
정규화와 다름. vertical partitioning 은 이미 정규화된 data를 분리하는 과정(논리적)
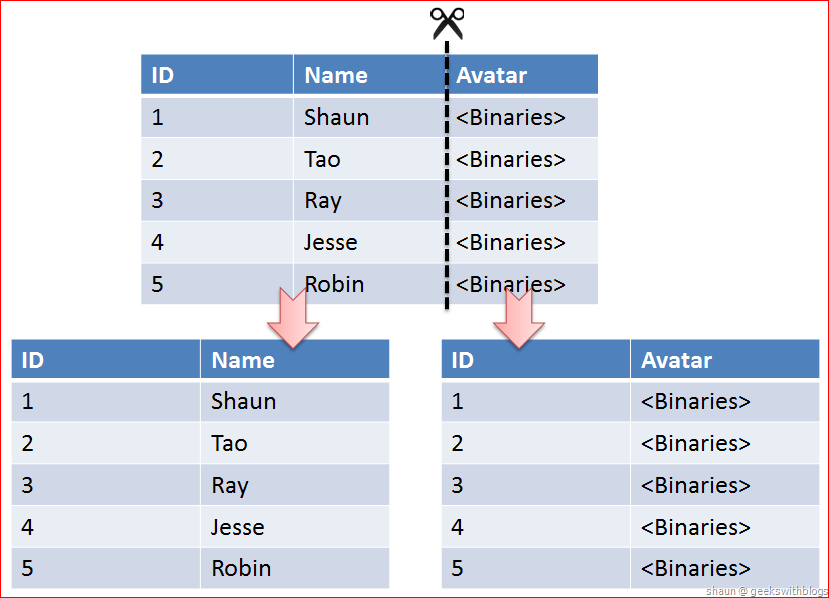
- 장점
- 자주 사용하는 컬럼을 분리시켜 성능 향상 가능.
클러스터링 (Clustering)
- 데이터 저장 시 데이터 액세스 효율을 향상시키기 위해, 동일한 성격의 데이터를 동일한 데이터 블록에 저장하는 물리적인 기법
- 저장 장치로부터 데이터를 읽어오는 시간을 줄이기 위해서 조인이나 자주 사용되는 테이블의 데이터를 저장 장치 내 같은 위치게 저장시키는 방법 (인덱스를 보완하는 방법)
장점
- 디스크 I/O를 줄여줌 (그룹된 컬럼 데이터 행들이 같은 데이터 블록에 저장되기 때문에)
- 클러스터된 테이블 사이에 조인이 발생할 경우 그 처리 시간이 단축됌.
- 클러스터키 열을 공유하여 한번만 저장해서 저장 영역의 사용을 줄인다.
단점
- 데이터 조회 성능을 향상시키지만, 데이터 갱신(입력,수정,삭제) 시 성능 저하
특징
- 클러스터 대상 테이블
- 자주 조인되는 테이블, 갱신이 자주 발생하지 않는 테이블을
- 클러스터 key 가 되기 좋은 column
- 데이터 값의 범위가 큰 컬럼. 분포도가 넓은 컬럼
- 테이블 간의 조인에 사용되는 컬럼
- 클러스터 key가 되기 나쁜 column
- 특정 데이터 값이 적은 컬럼 (이 경우엔, index 설정에 유리함)
- 자주 데이터 수정이 발생하는 컬럼
단일테이블 클러스터링
- 하나의 클러스터에 하나의 테이블만 생성
- 분포도 넓을 때 (처리 범위가 넓을 때) 효과적
- 여러건의 테이블 로우를 한 번의 스캔을 통하여 액세스 하므로 랜덤 엑세스 건수가 크게 줄어듬
다중테이블 클러스터링
- 하나의 단위 클러스터에 여러 개의 테이블을 함께 저장
- 조인이 많이 발생하는 경우 효과적
Leave a comment